Greedy Training |
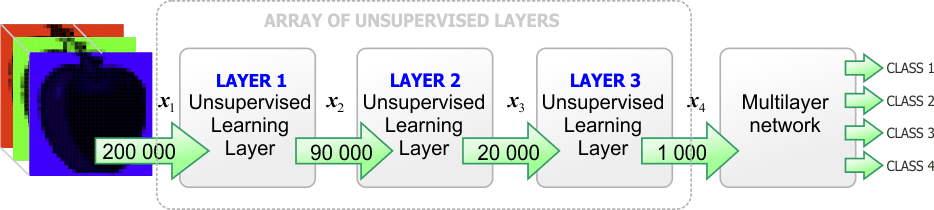
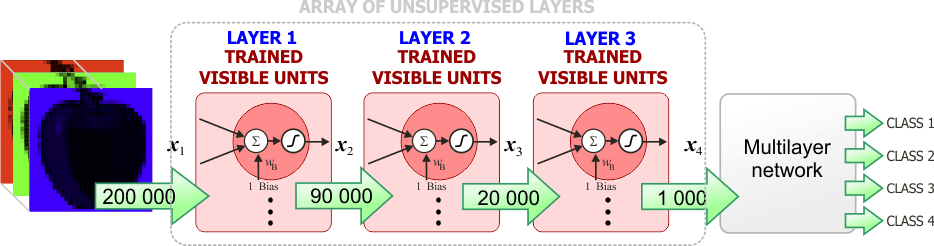
| The figure below shows a typical configuration for a deep neural network. The network has two parts: an array of unsupervised layers and a multilayer network. Greedy training is used to train deep learning networks. First, all the unsupervised layers are trained individually. Then, the multilayer network is trained using supervised training. Finally, all the layer of the network are trained together using supervised learning to fine tune the weights. La figura de abajo muestra una configuración típica para una red con aprendizaje profundo. La red tiene dos partes: un arreglo de capas sin supervisión y una red multicapa. El entrenamiento ambicioso se usa para entrenar las redes de aprendizaje profundo. Primero, todas las capas sin supervisión son entrenadas en forma individual. Entonces, la red multicapa es entrenada usando entrenamiento con supervisión. Finalmente, todos las capas de la red se entrenan juntas usando entrenamiento con supervisión para ajustar en forma fina los pesos. |
| Step 1 |
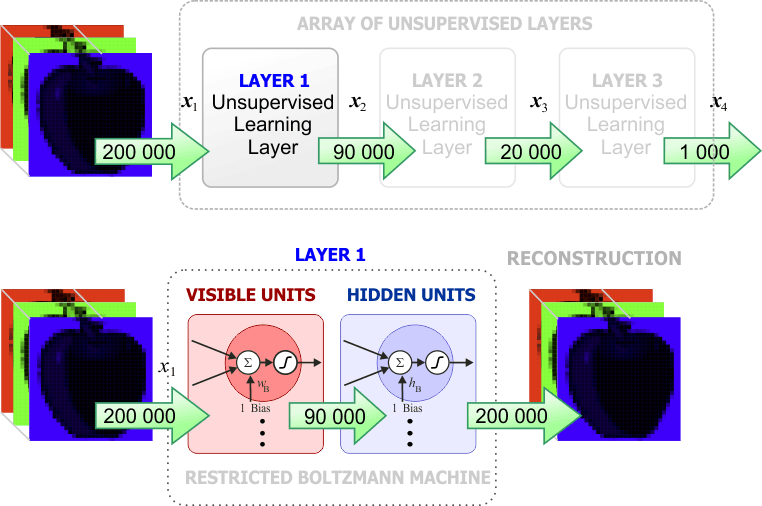
| Layer 1 is trained using unsupervised learning. In this case, a RBM is used to find the weights. The main purpose of the RBM is to reconstruct the original input of the network. Therefore, the target values of the training set are not used. Se entrena la capa 1 usando entrenamiento sin supervisión. En este caso, una RBM es usada para encontrar los pesos. El propósito principal de la RBM es reconstruir la entrada original de la red. Por lo tanto, los valores target del conjunto de datos de entrenamiento no se usan. |
| Step 2 |
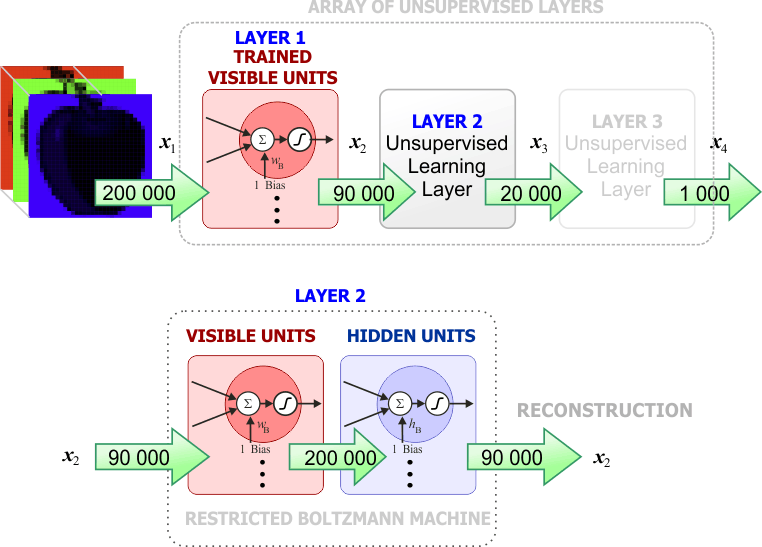
| After layer 1 has been trained, only the visible units of the trained RBM are incorporated to the array of unsupervised layers. Then, layer 2 is trained using unsupervised learning. Again, an RBM is used to find the weights. x2 is estimated by applying x1 to LAYER 1. Después de que la capa 1 se ha entrenado, sólo las unidades visibles de la RBM se incorporan al arreglo de la capas sin supervisión. Entonces, se entrena la capa 2 usando entrenamiento sin supervisión. Otra vez, una RBM es usada para encontrar los pesos. x2 se estimada aplicando los valores de x1 a la CAPA 1. |
| Step 3 |
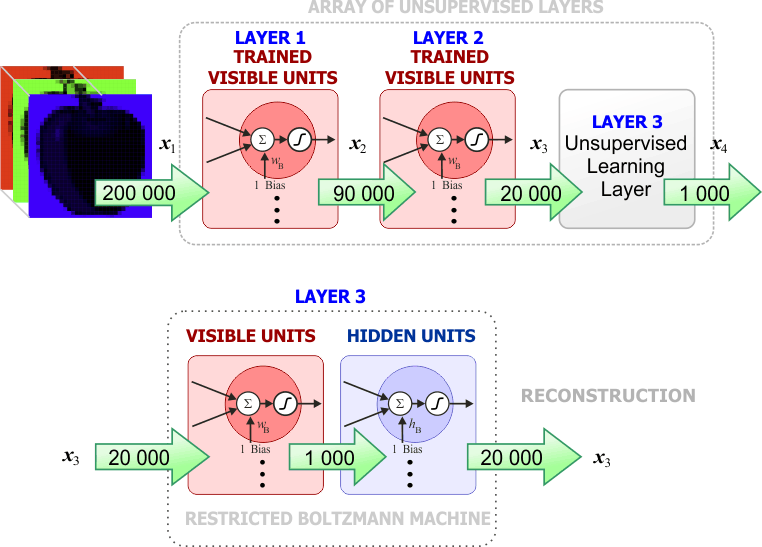
| We proceed to train all the layers in the array until all of them are trained. The figure below shows the training of the last layer in the array. Procedemos a entrenar todas las capas en el arreglo hasta que todas ellas han sido entrenadas. La figura de abajo muestra el entrenamiento de la última capa en el arreglo. |
| Step 4 |
| The values of x1 are applied to the array of unsupervised layers to compute the values of x4. At this point, the multilayer neural network is trained using the values of x4 and the target values of the training set. Finally, all the layers are trained together to fine tune the weights. Los valores de x1 se aplican al arreglo de capas sin supervisión para calcular los valores de x4. En este punto, la red neural multicapa se entrena usando los valores de x4 y los valores target del conjunto de datos de entrenamiento. Finalmente, todas las capas son entrenadas juntas para ajustar en forma fina los pesos. |
| Problem 1 |
| Download a research paper about greedy training. Write a 300 words summary to describe the method and the obtained results. Do not forget to include the title of the paper, the names of the authors, the journal name and the year of publication. Descargue un artículo de investigación sobre el entrenamiento ambicioso. Escriba un resumen de 300 palabras para describiendo el método y los resultados obtenidos. No se olvide de incluir el título del artículo, los nombres de los autores, el nombre de la revista y el año de publicación. |